AI and Machine Learning Overview
AWS Certified AI Practitioner (AIF-C01) certification study notes, this guide will help you with quick revision before the exam. it can use as study notes for your preparation.
DashboardAI and Machine Learning Overview
- AI and Machine Learning Overview
- What is AI?
- AI Components
- What is Machine Learning (ML)?
- What is Deep Leaning(DL)?
- What is Generative AI?
- What is the Transformer Model? (LLM)
- Diffusion Models
- Multi-Modal Models
- ML Terms You Need to Know
- Training Data
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Self-Supervised Learning
- Reinforcement Learning (RL)
- What is RLHF?
- Model Fit
- Bias and Variance
- Model Evaluation Metrics
- Inferencing
- Phases of a Machine Learning Project
- Hyperparameter Tuning
What is AI?
- Broad field focused on developing intelligent systems capable of performing tasks that typically require human intelligence
- Core Capabilities:
- Perception: Understanding visual/audio data
- Reasoning: Drawing logical conclusions
- Learning: Improving from experience
- Problem solving: Finding solutions to complex problems
- Decision making: Choosing optimal actions
- Umbrella term encompassing various techniques and approaches
- Common Use Cases:
- Computer vision for self-driving cars
- Facial recognition
- Fraud detection
- Intelligent Document Processing (IDP)
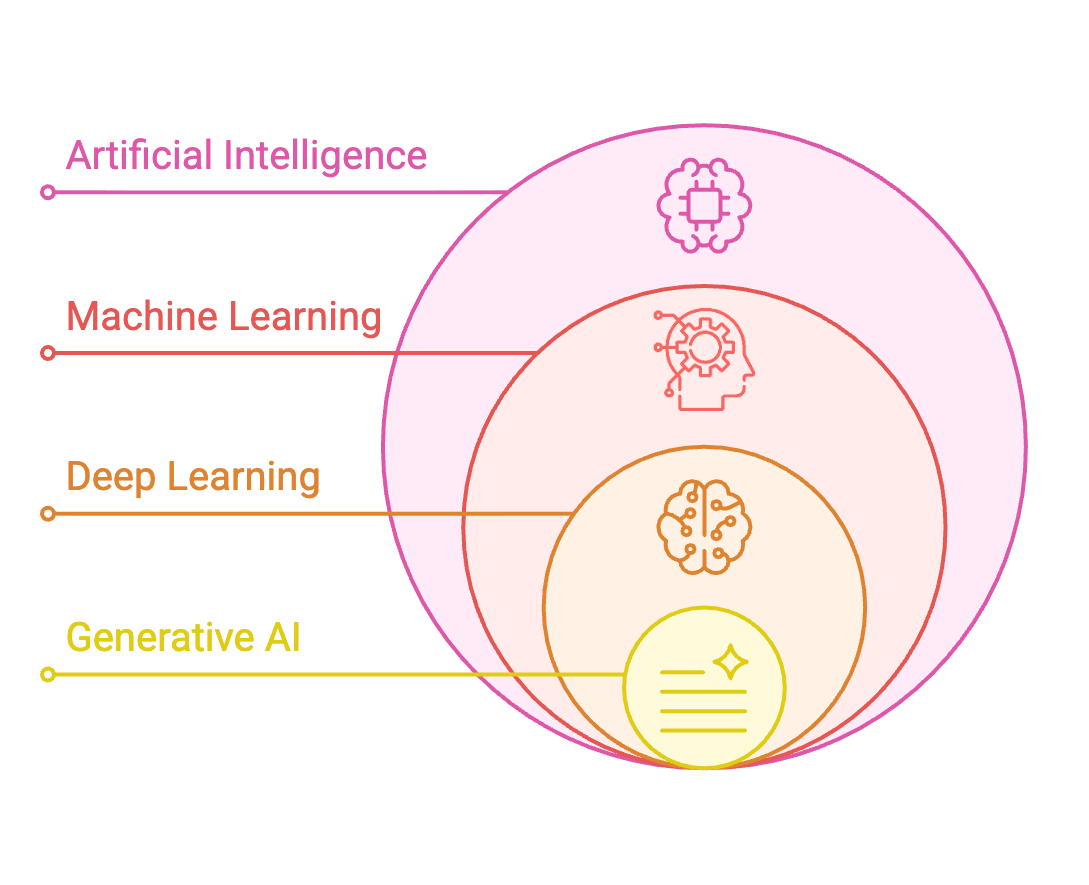
AI Components
- Data Layer: Collection and preparation
- Collect vast amounts of high-quality data
- Critical foundation for model performance
- Data quality determines model quality
- ML Framework and Algorithm Layer: Strategy and design
- Data scientists and engineers collaborate to understand:
- Use cases and business requirements
- Available frameworks and algorithms
- Best approaches to solve the problem
- Data scientists and engineers collaborate to understand:
- Model Layer: Implementation and training
- Implement the model structure
- Set parameters and configurations
- Train the model using optimization functions
- Tune and validate performance
- Application Layer: Deployment and serving
- Deploy trained model to production
- Expose model capabilities to end users
- Monitor performance in real-world scenarios
- Maintain and update as needed
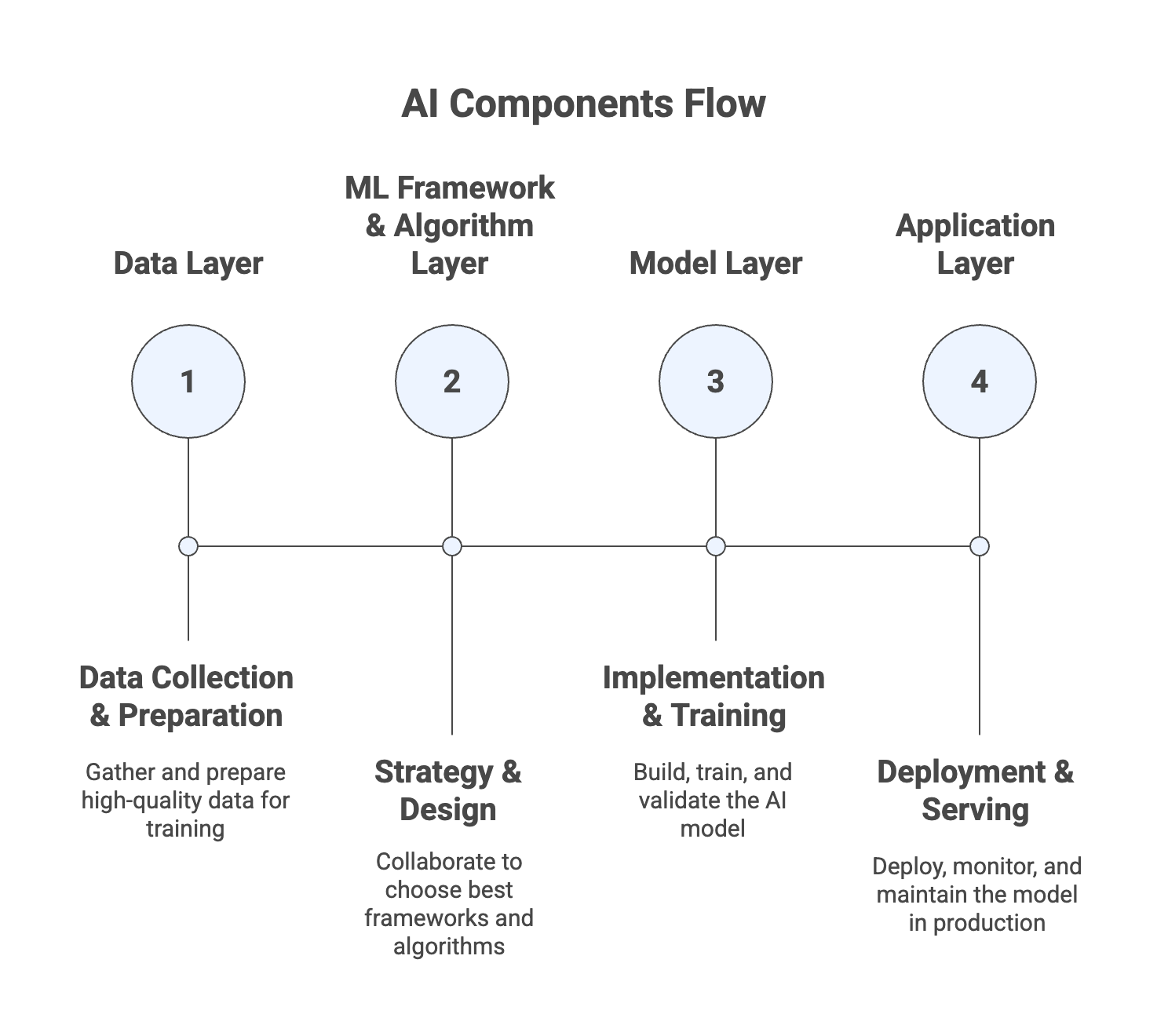
What is Machine Learning (ML)?
- Type of AI that enables systems to learn and improve from data without explicit programming
- Machines learn patterns from data rather than following programmed rules
- Build methods that allow machines to make predictions and decisions based on learned patterns
- Data-driven: Improves performance by processing large datasets
- Pattern recognition: Identifies patterns and relationships in data
- Predictive capability: Makes predictions on new, unseen data
- Non-programmatic: Learns without explicit rule programming
- AI ≠ ML: AI is broader, ML is one approach within AI
- Most modern AI systems leverage ML techniques
What is Deep Leaning(DL)?
- Subset of machine learning inspired by the structure and function of the human brain
- Uses neurons and synapses (like the brain) to train models
- Processes more complex patterns than traditional ML techniques
- Deep refers to multiple layers of learning/hidden layers
- Handles more intricate relationships than traditional regression/classification
- Automatically extracts features without manual feature engineering
- Leverages increasing data and computational resources effectively
- Key Requirements:
- Large Datasets: Needs substantial amounts of training data for good performance
- Computational Resources: Training is computationally intensive, typically using GPUs (Graphics Processing Units)
- Time: Training deep models requires significant time investment
- Applications
- Computer Vision
- Image classification: Categorizing images into classes
- Object detection: Locating and identifying objects in images
- Image segmentation: Partitioning images into meaningful regions
- Facial recognition: Identifying faces in images
- Natural Language Processing (NLP)
- Text classification: Categorizing text documents
- Sentiment analysis: Determining emotional tone of text
- Machine translation: Translating between languages
- Language generation: Creating human-like text
- Computer Vision
Neural Networks - how do they work?
- Computational models composed of interconnected layers of nodes (neurons) that process and transform input data
- Processes input data through multiple layers, extracting features and making predictions
- Nodes are organized in layers
- When the neural network sees a lot of data, it identifies patterns and changes the connections between the nodes
- Nodes are talking to each other, by passing on (or not) data to the next layer
- The math and parameters tuning behind it is beyond the level of this course
- Neural networks may have billions of nodes
- Input Layer:
- Receives raw input data
- Each neuron represents one feature of input data
- No processing occurs here
- Hidden Layers:
- Intermediate layers between input and output
- Multiple hidden layers create deep networks
- Perform computations and extract features from input data
- Different layers learn different levels of abstraction
- Output Layer:
- Final layer producing the prediction or classification
- Structure depends on task:
- Regression: Single neuron with continuous output
- Classification: Multiple neurons with probability outputs
What is Generative AI?
- Generative AI is a branch of Deep Learning
- The idea is simple: you train a model on existing data, and it learns to create new data that looks similar
- Think of it like teaching someone to paint by showing them thousands of paintings
- Once trained, it can create brand new content that follows the same patterns
What is the Transformer Model? (LLM)
- Architecture that processes entire sequences at once rather than sequentially word-by-word
- Revolutionary approach enabling efficient, parallel text processing
- Faster training and better handling of long-range dependencies
- Reduces training time significantly
- It gives relative importance to specific words in a sentence
- Scales well to large datasets and models
- Transformer-Based LLMs
- Powerful models that can understand and generate human-like text
- Trained on vast amounts of text data from the internet, books, and other sources, and learn patterns and relationships between words and phrases
- Examples:
- Google BERT: Bidirectional Encoder Representations from Transformers
- OpenAI ChatGPT: Chat Generative Pre-Trained Transformer
- Modern transformers can have billions of parameters
- Can be adapted to many NLP tasks through fine-tuning
Diffusion Models
- Used in machine learning, particularly for generating complex data such as images, audio, and even text
- Key concepts:
- Generative Modeling: learn the underlying distribution of a dataset and generate new data points that are similar to the training data
- Forward Diffusion Process: the diffusion process begins by gradually adding noise to the data (e.g., an image) over a series of steps until the data is completely transformed into noise
- Reverse Diffusion Process: generative part of the model, where the goal is to start from pure noise and iteratively remove the noise, effectively reversing the forward diffusion process, to generate new data that resembles the original training data
Multi-Modal Models
- Models that can process and generate multiple types of data simultaneously
- Handle diverse input and output formats in single model
- Combines information from different modalities for richer understanding
- Examples:
- Image + Audio → Video: Take image of cat and audio file, generate video of cat speaking the audio
- Image → Text: Analyze image and generate descriptive caption
- Text + Image → Text: Analyze both and generate combined interpretation
ML Terms You Need to Know
- GPT (Generative Pre-trained Transformer) – generate human text or computer code based on input prompts
- BERT (Bidirectional Encoder Representations from Transformers) – similar intent to GPT, but reads the text in two directions
- RNN (Recurrent Neural Network) – meant for sequential data such as time-series or text, useful in speech recognition, time-series prediction
- ResNet (Residual Network) – Deep Convolutional Neural Network (CNN) used for image recognition tasks, object detection, facial recognition
- SVM (Support Vector Machine) – ML algorithm for classification and regression
- WaveNet – model to generate raw audio waveform, used in Speech Synthesis
- GAN (Generative Adversarial Network) – models used to generate synthetic data such as images, videos or sounds that resemble the training data. Helpful for data augmentation
- XGBoost (Extreme Gradient Boosting) – an implementation of gradient boosting
Training Data
- Good training data is essential for building effective machine learning models
- Poor quality data results in poor model performance
- Good data must be defined appropriately for the specific use case
- Training data selection and preparation is one of the most critical stages in building an effective model
- There are several options to model our data, which will impact the types of algorithms we can use to train our models
- Labeled vs. Unlabeled Data
- Structured vs. Unstructured Data
Labeled Data
- Consists of both input features and output labels
- Each data point has an associated correct answer
- Example: Dataset of animal images where each image is labeled as “dog” or “cat”
- Input feature: The image itself
- Output label: The animal type
- Used for supervised learning
- Algorithm learns to map inputs to known outputs by studying labeled examples
- When correct answers are known and can be applied to new data
- Labeling large datasets can be costly and time-consuming
Unlabeled Data
- Includes only input features without any output labels
- Raw data without associated correct answers
- Example: Collection of images without labels indicating whether they are cats or dogs, etc…
- Used for unsupervised learning
- Algorithm must identify patterns or structures within the data itself (e.g., grouping similar images)
Structured Data
- Organized in a defined format, typically rows and columns
- Similar to a spreadsheet with clearly defined fields
- Other type of structured data is Time Series Data, where data points are collected and recorded at successive points in time
Unstructured Data
- Does not follow a specific format or structure
- Often text-heavy or multimedia content without predefined organization
- Text Data: Online articles, social media posts, customer reviews, long-form feedback, etc…
- Image Data: Photos and visual content, consists of pixels without organized metadata
- Other Types: Audio files and speech recordings, video content, free-form text documents,
- Requires specialized algorithms to extract information
Supervised Learning
- Learn a mapping function that can predict the output for new, unseen input data
- Requires labeled data (input features + output labels)
- Very powerful for prediction tasks
- Obtaining labeled data for millions of data points can be difficult and costly
- Trains model on labeled examples so it learns patterns connecting inputs to outputs
Regression
- Predict continuous numeric values based on input data
- Continuous variable that can take any value within a range
- Examples:
- Predicting house prices based on size, location, features
- Predicting stock prices
- Weather forecasting (temperature, rainfall)
- Predicting customer spending behavior
Classification
- Used to predict categorical labels of input data
- Output variable is a discrete variable representing specific categories or classes
- Use cases: scenarios where decisions or predictions need to be made between distinct categories (fraud, image classification, customer retention, diagnostics)
- Types of Classification
- Binary Classification:
- Two possible classes
- Example: Spam/Not spam, Fraud/Not fraud
- Yes/No decisions
- Multiclass Classification:
- More than two classes
- Example: Animals (cat, dog, giraffe)
- Example: Image recognition (0-9 digits)
- Multi-label Classification:
- Multiple labels per instance
- Example: Movie can be both “Action” and “Comedy”
- Example: Document tagged as both “urgent” and “financial”
- Binary Classification:
- Key algorithm: K-nearest neighbors (k-NN) model
Training vs. Validation vs. Test Sets
- Training Set: 60-80% of data
- Used to train the model
- Model learns patterns from this data
- Most important for learning
- Validation Set: 10-20% of data
- Used to tune model parameters
- Validate performance during training
- Helps prevent overfitting
- Test different configurations
- Test Set: 10-20% of data
- Used to evaluate final model accuracy
- Never seen by model during training
- Represents unseen data performance
- Final evaluation metric
Feature Engineering
- Process of using domain knowledge to select and transform raw data into meaningful features
- Helps enhancing the performance of machine learning models
- Techniques
- Feature Extraction:
- extract useful information from raw data
- Example: Calculate age from birth date, extract hour from timestamp, calculate BMI from height and weight
- Feature Selection:
- Choose subset of relevant features
- Remove redundant or irrelevant features
- Improve model efficiency and interpretability
- Example: Select important predictors in regression model
- Feature Transformation:
- Transform data for better model performance
- such as normalizing numerical data
- Feature Extraction:
Feature Engineering on Structured Data
- Structured Data (Tabular Data)
- Example: Predicting house prices based on features like size, location, and number of rooms
- Feature Engineering Tasks
- Feature Creation – deriving new features like “price per square foot”
- Feature Selection – identifying and retaining important features such as location or number of bedrooms
- Feature Transformation – normalizing features to ensure they are on a similar scale, which helps algorithms like gradient descent converge faster
Feature Engineering on Unstructured Data
- Unstructured Data (Text, Images, Audio, Video)
- Examples: sentiment analysis of customer reviews
- Feature Engineering Tasks
- Text Data – converting text into numerical features using techniques like TF-IDF or word embeddings
- Image Data – extracting features from images using techniques like edge detection, or textures using techniques like convolutional neural networks (CNNs)
Unsupervised Learning
- The goal is to discover inherent patterns, structures, or relationships within the input data
- The machine must uncover and create the groups itself, but humans still put labels on the output groups
- Common Techniques: Clustering, association rule learning, anomaly detection
- Clustering use cases: customer segmentation, targeted marketing, recommender systems
- Feature Engineering can help improve the quality of the training
Clustering Technique
- Groups similar data points together into clusters based on their features
- Find natural groupings in data without predefined labels
- Algorithm analyzes similarity between data points and groups them accordingly
- Example: Customer Segmentation
- Scenario: e-commerce company wants to segment its customers into groups based on their purchasing behaviors
- Data: A dataset containing customer purchasing history
- Goal: Identify distinct groups of customers based on their purchasing behavior
- Technique: K-means Clustering
- Outcome: Company can target each segment with different marketing strategies
Association Rule Learning
- The goal is to understand which products are frequently bought together
- Market basket analysis in retail environments
- Optimize product placement and joint promotions
- Example:
- Scenario: supermarket wants to understand which products are frequently bought together
- Data: A dataset containing customer purchasing history
- Goal: Identify which products are frequently bought together
- Technique: Apriori algorithm
- Outcome: Supermarket can optimize product placement and joint promotions to increase sales
Anomaly Detection
- The goal is to identify data points that deviate significantly from normal patterns
- Flag unusual or suspicious transactions/events
- Fraud detection, security monitoring
- Example:
- Scenario: credit card company wants to detect fraudulent transactions
- Data: A dataset containing credit card transactions
- Goal: Identify fraudulent transactions
- Technique: Isolation Forest
- Outcome: Credit card company can detect fraudulent transactions and prevent fraud
Semi-Supervised Learning
- Hybrid approach combining small amounts of labeled data with large amounts of unlabeled data
- Leverage both labeled and unlabeled data to build effective models
- After that, the partially trained algorithm itself labels the unlabeled data
- This is called pseudo-labeling
- The model is then re-trained on the resulting data mix without being explicitly programmed
Self-Supervised Learning
- Model learns from large amounts of unlabeled data by generating its own pseudo-labels
- Data essentially labels itself without requiring human annotation
- Addresses the problem of expensive manual data labeling
- Widely used in NLP (to create the BERT and GPT models for example) and in image recognition tasks
- Difference from Unsupervised: Produces labels from data itself; uses those labels for supervised tasks
- Enables advanced models like GPT without costly human-labeled datasets
- How It Works
- Unlabeled Data: Start with large amounts of raw, unlabeled data (text, images, audio)
- Pseudo-Labels: Model automatically generates labels from the data itself
- Self-Training: Model learns by predicting these auto-generated labels
- Knowledge Transfer: Learned knowledge transferred to downstream supervised tasks
Reinforcement Learning (RL)
- Machine learning type where an agent learns to make decisions by performing actions in an environment
- Maximize cumulative reward over time
- Agent learns through trial and error, receiving feedback (rewards/penalties)
- Iterative process of observation, action, reward, and policy update
- Like training a robot to find its way through a maze
- Key Concepts
- Agent - Learner or decision maker(Example: Robot trying to navigate a maze)
- Environment - External system the agent interacts with(Example: The maze itself)
- Action - Choices made by the agent(Example: Moving up, down, left, or right)
- Reward - Feedback from the environment based on agent action
- State - Current situation of the environment(Example: Robot’s current position)
- Policy - Strategy to determine action based on state(Example: Move up if the position is not a wall)
How Does Reinforcement Learning Work?
- Learning Process
- The Agent observes the current State of the environment
- It selects an Action based on its Policy
- The environment transitions to a new State and provides a Reward
- The Agent updates its Policy to improve future decisions
- Goal: Maximize cumulative reward over time
Applications of Reinforcement Learning
- Gaming – teaching AI to play complex games (e.g., Chess, Go)
- Robotics – navigating and manipulating objects in dynamic environments
- Finance – portfolio management and trading strategies
- Healthcare – optimizing treatment plans
- Autonomous Vehicles – path planning and decision-making
What is RLHF?
- Reinforcement Learning from Human Feedback (RLHF)
- Utilize human feedback to help ML models self-learn more efficiently
- Better align models with human goals, wants, and needs
- Human feedback incorporated directly into reward function
- Widely used in generative AI and large language models (LLMs)
- Significantly enhances model performance
- RLHF incorporates human feedback in the reward function, to be more aligned with human goals, wants and needs
- First, the model’s responses are compared to human’s responses
- Then, a human assesses the quality of the model’s responses
- Example: grading text translations from “technically correct” to “human”
How does RLHF work?
- Step 1: Data Collection
- Collect human-generated prompts
- Create ideal/human responses for each prompt
- Example Prompt: “Where is the location of the HR department in Boston?”
- Step 2: Supervised fine-tuning of a language model
- Fine-tune an existing model with internal knowledge
- Then the model creates responses for the human-generated prompts
- Responses are mathematically compared to human-generated answers
- Step 3: Build Separate Reward Model
- Humans see two different model responses
- Humans indicate which response they prefer
- Reward model learns to fit human preferences
- Automatically understands how humans choose between responses
- Step 4: Reinforcement Learning Optimization
- Use the reward model as a reward function for RL
- Fully automated because human feedback already embedded
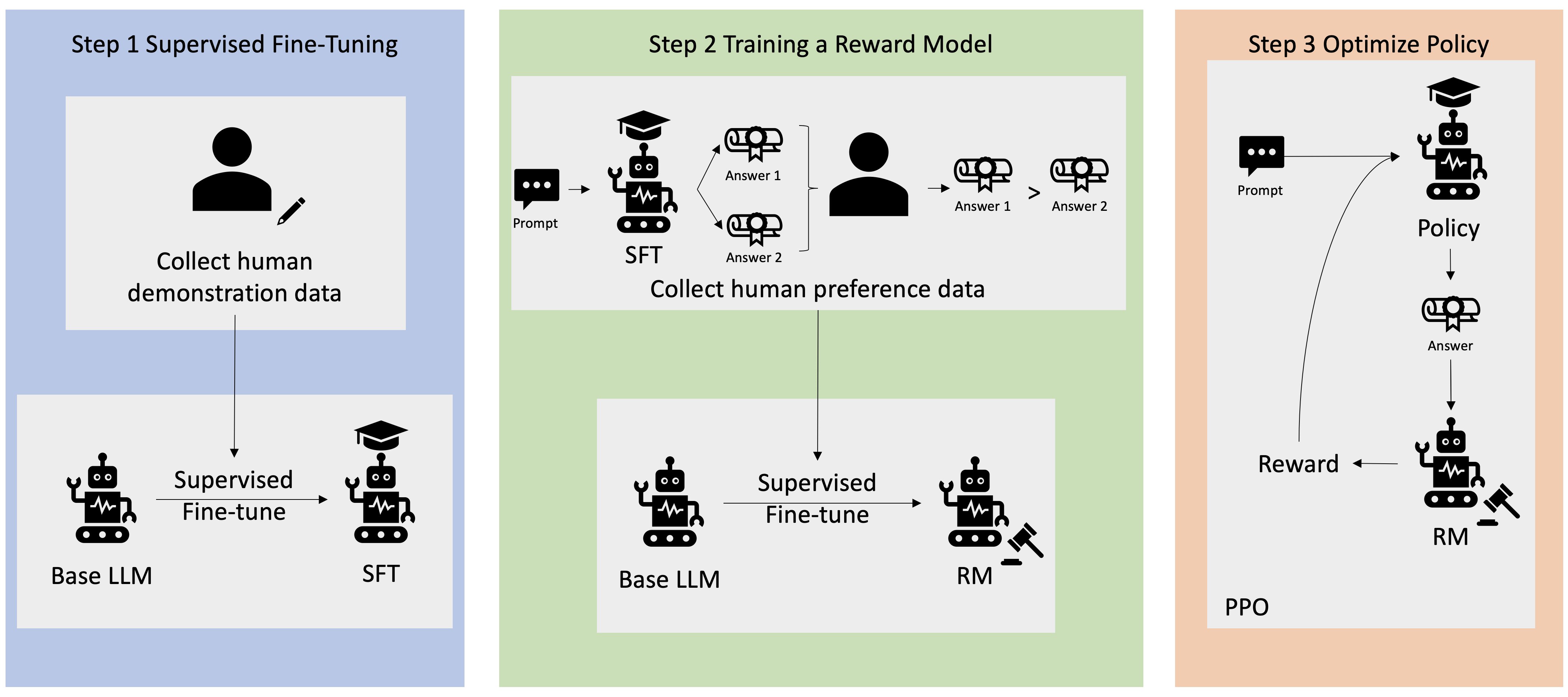
Source: https://aws.amazon.com/what-is/reinforcement-learning-from-human-feedback/
Model Fit
- In case our model has a bad performance, we need to take a look at the model fit
- Overfitting:
- The model performs very well on the training data
- It does not perform well on the evaluation data
- Underfitting:
- The model performs poorly on the training data
- Could be a problem of having a model that is too simple or the data has poor features
- Balanced:
- Neither overfitting or underfitting
- The model performs well on the training and evaluation data
Bias and Variance
- Bias:
- Difference or error between the predicted and actual value
- Occurs due to the wrong choice in the ML process
- High Bias:
- The model des not closely match the training data
- Example: linear regression function on a non-linear dataset
- Considered as underfitting
- Reducing Bias:
- Use a more complex model
- Increase the number of features
- Variance:
- Represents how much the performance of a model changes if trained on a different dataset which has a similar distribution
- High Variance:
- The model is very sensitive to changes in the training data
- This is the case when we face overfitting: performs well on training data, but poorly on unseen test data
- Reducing variance:
- Feature selection: use less, more important features
- Split data into training and test sets multiple times
Model Evaluation Metrics
Confusion Matrix
- A confusion matrix can help understand the more nuanced results of a model
- Binary confusion matrix:
| Actual YES | Actual NO | |
|---|---|---|
| Predicted YES | TRUE POSITIVES | FALSE POSITIVES |
| Predicted NO | FALSE NEGATIVES | TRUE NEGATIVES |
- True Positives (TP): Predicted positive, actually positive (Correct!)
- False Positives (FP): Predicted positive, actually negative (Wrong!)
- True Negatives (TN): Predicted negative, actually negative (Correct!)
- False Negatives (FN): Predicted negative, actually positive (Wrong!)
Key Classification Metrics
- Measuring models:
- Accuracy: (TRUE POSITIVES + TRUE NEGATIVES) / (TRUE POSITIVES + FALSE POSITIVES + TRUE NEGATIVES + FALSE NEGATIVES)
- Measures the fraction of correct predictions; the range is 0 to 1
- A larger value indicates better predictive accuracy
- Recall: TRUE POSITIVES / (TRUE POSITIVES + FALSE NEGATIVES)
- AKA Sensitivity, True Positive rate, Completeness
- It is the percent of positive rightly predicted
- It is a good choice when we care about the false negatives, ex. fraud detection
- Precision: TRUE POSITIVES / (TRUE POSITIVES + FALSE POSITIVES)
- AKA Correct Positives
- It is the percent of relevant results
- It is a good choice when we care about false positives, ex. medical screening, drug testing
- Other metrics:
- Specificity: TRUE NEGATIVES / (TRUE NEGATIVES + FALSE POSITIVES) (True negative rate)
- F1 score:
- 2 * TRUE POSITIVES / 2 * TRUE POSITIVES + FALSE POSITIVES + FALSE NEGATIVES
- 2 * (Precision * Recall) / (Precision + Recall)
- It is the harmonic mean of precision and sensitivity
- Good choice when we care about precision and recall
- Best for: Imbalanced datasets where you need balance between precision and recall
- RMSE - Root mean squared error
- It is used for accuracy measurement
- It only cares about right and wrong answers
- Accuracy: (TRUE POSITIVES + TRUE NEGATIVES) / (TRUE POSITIVES + FALSE POSITIVES + TRUE NEGATIVES + FALSE NEGATIVES)
AUC-ROC - Area under the curve-receiver operator curve
- ROC Curve - Receiver Operating Characteristic Curve
- It is a plot of true positive rate (sensitivity/recall) vs. false positive rate (Specificity) at various threshold settings
- Points above the diagonal represent good classification (better than random)
- The ideal curve would be a point in the upper-left corner
- The more it’s “bent” towards upper-left, the better
- AUC: the area under ROC curve - Area Under the Curve
- Equal to probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance
- ROC AUC of 0.5 is useless classifier, 1.0 is perfect
- Commonly used metric for comparing classifiers
- Example of usage of Confusion Matrix with measuring models: https://aws.amazon.com/blogs/machine-learning/predicting-customer-churn-with-amazon-machine-learning/
- Best for:
- Comparing different models
- Choosing optimal classification thresholds
- Imbalanced datasets (more meaningful than accuracy)
Regression Metrics
- MAE, MAPE, RMSE, R² (R Squared) are used for evaluating models that predict a continuous value (i.e., regressions)
- Example: Imagine you’re trying to predict how well students do on a test based on how many hours they study.
- Metrics used measure the quality of a regression model
- MAE (Mean Absolute Error): measures the average magnitude of errors between the predicted values and the actual values.
- MAPE (Mean Absolute Percentage Error): used to assess the accuracy of a predictive model by calculating the average percentage error between the predicted values and the actual values. MAPE expresses the error as a percentage, making it easier to interpret across different scales
- RMSE (Root Mean Squared Error): measures the average magnitude of the error between the predicted values and the actual values, with a higher emphasis on larger errors
- R Squared(R²): explains variance in our model. R² close to 1 means predictions are good
- If R² is 0.8, this means that 80% of the changes in test scores can be explained by how much students studied, and the remaining 20% is due to other factors like natural ability or luck
Metrics for Evaluating LLMs
- Perplexity loss: measures how well the model can predict the next word in a sequence of text
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE): set of metrics used in the field of natural language processing to evaluate the quality of machine-generated text
- There are several variants of ROUGE metrics:
- ROUGE-1, ROUGE-2, ROUGE-N: primary ROUGE metric, measures the overlap of n-grams between the system-generated and reference texts
- ROUGE-L: calculates the longest common subsequence between the system-generated text and the reference text
- ROUGE-L-Sum: used mainly to evaluate summarization systems. Takes into account the order of words in the text, which is important in text summarization tasks
Inferencing
- Inferencing is when a model makes predictions on new data
- Types of inferencing:
- Real Time
- Computers have to make decisions quickly as data arrives
- Speed is preferred over perfect accuracy
- Example: chatbots
- Batch
- Large amount of data that is being analyzed all at once
- Often used for data analysis and reporting
- Speed of the results is usually not a concern, and accuracy is
- Example: predicting customer behavior
- Real Time
Inferencing at the Edge
- Edge devices are usually devices with less computing power that are close to where the data is generated, in places where internet connections can be limited
- Example: a chatbot that is running on a phone
- Small Language Model (SLM) on the edge device
- Very low latency
- Low compute footprint
- Offline capability, local inference
- Large Language Model (LLM) on a remote server
- More powerful model
- Higher latency
- Must be online to be accessed
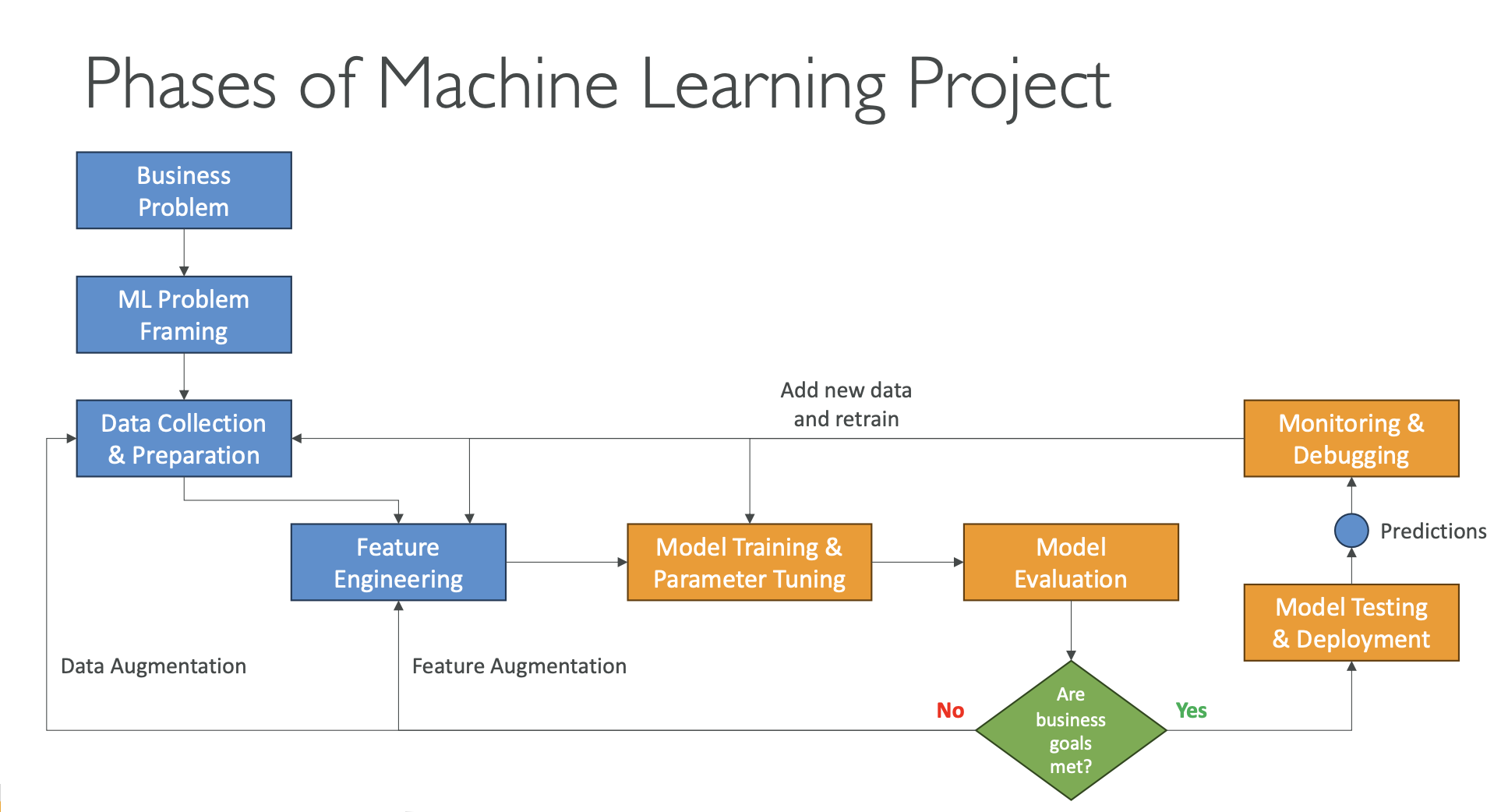
Phases of a Machine Learning Project
- Define Business Goals
- Identify the business problem, expected value, and success criteria.
- Set clear KPIs (Key Performance Indicators) to measure success.
- Stakeholders align on goals, budget, data availability, and constraints.
- Frame the ML Problem
- Convert the business problem into a machine learning task (classification, regression, etc.).
- Validate whether ML is the right solution.
- Collaboration between data scientists, data engineers, ML architects, and domain experts (SMEs).
- Data Processing
- Collect, clean, and integrate data into a usable, centralized form.
- Perform data preprocessing (handling missing values, encoding, scaling).
- Use data visualization to understand structure, trends, and issues.
- Feature Engineering: create, transform, and select important input variables.
- Exploratory Data Analysis (EDA)
- Explore patterns and relationships using charts, plots, and summaries.
- Create a correlation matrix to identify highly related features and potential predictors.
- Helps decide which features matter and which can be removed.
- Model Development
- Train multiple models, tune hyperparameters, and compare performance.
- Evaluate using appropriate metrics (accuracy, F1, AUC, RMSE, etc.).
- Iterative process: try new features, fix data issues, and improve model quality.
- Retraining (Model Improvement)
- Revisit data quality, feature selection, and hyperparameters.
- Add new data or features if performance drops.
- Improve robustness and reduce bias or drift.
- Deployment
- Deploy the model once performance meets KPIs.
- Choose a deployment strategy:
- Real-time, batch, serverless, asynchronous, on-premise, etc.
- Model becomes available for predictions (inference).
- Monitoring
- Track model performance, data quality, latency, and resource usage.
- Detect early signs of model drift, inaccuracies, or system failures.
- Enable logging, alerts, and diagnostics to debug issues.
- Continuous Iteration
- ML lifecycle is ongoing: update model as new data arrives.
- Business goals or requirements may evolve.
- Continuous iteration keeps the model accurate, stable, and relevant over time.
Hyperparameter Tuning
- What are Hyperparameters?
- Settings that define how a model learns and the structure of the model.
- They are set before training starts.
- Examples include:
- Learning rate
- Batch size
- Number of epochs
- Regularization strength
- What is Hyperparameter Tuning?
- The process of finding the best combination of hyperparameter values to maximize model performance.
- Helps to:
- Improve accuracy
- Reduce overfitting
- Increase generalization to unseen data
- How Do We Tune Hyperparameters?
- Grid Search – tries all possible combinations
- Random Search – samples random combinations
- Automated Tuning Services – e.g., AWS SageMaker Automatic Model Tuning (AMT)
Important Hyperparameters
- Learning Rate
- Controls the size of the steps when updating model weights.
- High learning rate: faster but may overshoot the optimum.
- Low learning rate: slower but more stable and precise.
- Batch Size
- Number of samples processed before the model updates its weights.
- Small batch: more stable learning, slower.
- Large batch: faster but may be less stable.
- Number of Epochs
- Total number of times the model trains over the entire dataset.
- Too few: underfitting.
- Too many: overfitting.
- Regularization
- Helps balance between simple vs. complex models.
- Increase regularization → reduces overfitting by penalizing overly complex patterns.
What to Do If the Model Is Overfitting?
- The model performs very well on training data but poorly on new, unseen data.
- It occurs due to:
- Training data size is too small and does not represent all possible input values
- Training too long on the same dataset
- Model complexity is high and learns from the noise within the training data
- How to Reduce Overfitting
- Increase the size or diversity of the training data
- Apply early stopping
- Use data augmentation(to increase diversity in the dataset)
- Adjust hyperparameters(but you can’t “add” them)